MySQL 常见问题(一)
Mysql FAQ

1 主键和 UNIQUE 的区别
主键和UNIQUE约束都能保证某个列或者列组合的唯一性,但是:
- 一张表中只能定义一个主键,却可以定义多个
UNIQUE约束! - 主键列不允许存放
NULL,而声明了UNIQUE属性的列可以存放NULL,而且NULL可以重复地出现在多条记录中。
2 结束符
delimiter EOF # 将结束符改为 EOF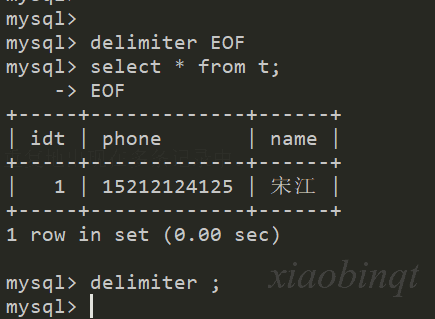
由☝️图可知,将默认的结束符从 ; 改为 EOF。
3 什么是外键
如果A表中的某个列或者某些列依赖与B表中的某个列或者某些列,那么就称A表为子表,B表为父表。子表和父表可以使用外键来关联起来。
父表中被子表依赖的列或者列组合必须建立索引,如果该列或者列组合已经是主键或者有UNIQUE属性,那么也就被默认建立了索引。
定义外键的语法:
CONSTRAINT [外键名称] FOREIGN KEY(列1, 列2, ...) REFERENCES 父表名(父列1, 父列2, ...);3.1 示例
CREATE TABLE student_score
(
number INT, -- 学号
subject VARCHAR(30),
score TINYINT,
PRIMARY KEY (number, subject),
CONSTRAINT FOREIGN KEY (number) REFERENCES student_info (number)
);☝️ 如上,在对student_score表插入数据的时候,MySQL 都会检查插入的学号是否能在student_info
表中找到,如果找不到则会报错,因为student_score表中的number
列依赖于student_info表的number列,也就是,如果没有这个学生,何来成绩?
4 ZEROFILL
对于无符号整数类型的列,可以在查询数据的时候让数字左边补 0,如果想实现这个效果需要给该列加一个ZEROFILL属性:
CREATE TABLE zerofill_table
(
i1 INT(10) UNSIGNED ZEROFILL,
i2 INT UNSIGNED
);INT后边的(5),这个 5 就是显示宽度,默认是10,也就是 INT 也 INT(10) 效果是一样的。
4.1 注意
- 该列必须是整数类型
- 该列必须有
UNSIGNED ZEROFILL的属性 - 该列的实际值的位数必须小于显示宽度
- 在创建表的时候,如果声明了
ZEROFILL属性的列没有声明UNSIGNED属性,MySQL 会为该列自动生成UNSIGNED属性 - 显示宽度并不会影响实际类型的实际存储空间
- 对于没有声明
ZEROFILL属性的列,显示宽度没有任何作用,只有在查询声明了ZEROFILL属性的列时,显示宽度才会起作用,否则可以忽略显示宽度这个东西的存在。
5 limit、offset 区别
从 0 开始计数,第1条记录在 MYSQL 中是第 0 条。
limit 和 offset 都可以用来限制查询条数,一般用做分页。
- 当 limit 后面跟一个参数的时候,该参数表示要取的数据的数量
select *
from user limit 3表示直接取前三条数据。
- 当 limit 后面跟两个参数的时候,第一个数表示开始行,后一位表示要取的数量,例如
select *
from user limit 1,3;从 0 行开始计算,取第 1 - 3 条数据,也就是取 1,2,3 三条数据。
- 当 limit 和 offset 组合使用的时候,limit 后面只能有一个参数,表示要取的的数量,offset 表示开始行。
select *
from user limit 3
offset 1;从 0 行开始计算,取第 1 - 3 条数据,也就是取 1,2,3 三条数据。
6 常用函数
6.1 文本处理函数
| 名称 | 调用示例 | 示例结果 | 描述 |
|---|---|---|---|
LEFT |
LEFT('abc123', 3) |
abc |
给定字符串从左边取指定长度的子串 |
RIGHT |
RIGHT('abc123', 3) |
123 |
给定字符串从右边取指定长度的子串 |
LENGTH |
LENGTH('abc') |
3 |
给定字符串的长度 |
LOWER |
LOWER('ABC') |
abc |
给定字符串的小写格式 |
UPPER |
UPPER('abc') |
ABC |
给定字符串的大写格式 |
LTRIM |
LTRIM(' abc') |
abc |
给定字符串左边空格去除后的格式 |
RTRIM |
RTRIM('abc ') |
abc |
给定字符串右边空格去除后的格式 |
SUBSTRING |
SUBSTRING('abc123', 2, 3) |
bc1 |
给定字符串从指定位置截取指定长度的子串 |
CONCAT |
CONCAT('abc', '123', 'xyz') |
abc123xyz |
将给定的各个字符串拼接成一个新字符串 |
6.2 时间处理函数
| 名称 | 调用示例 | 示例结果 | 描述 |
|---|---|---|---|
NOW |
NOW() |
2019-08-16 17:10:43 |
返回当前日期和时间 |
CURDATE |
CURDATE() |
2019-08-16 |
返回当前日期 |
CURTIME |
CURTIME() |
17:10:43 |
返回当前时间 |
DATE |
DATE('2019-08-16 17:10:43') |
2019-08-16 |
将给定日期和时间值的日期提取出来 |
DATE_ADD |
DATE_ADD('2019-08-16 17:10:43', INTERVAL 2 DAY) |
2019-08-18 17:10:43 |
将给定的日期和时间值添加指定的时间间隔 |
DATE_SUB |
DATE_SUB('2019-08-16 17:10:43', INTERVAL 2 DAY) |
2019-08-14 17:10:43 |
将给定的日期和时间值减去指定的时间间隔 |
DATEDIFF |
DATEDIFF('2019-08-16', '2019-08-17') |
-1 |
返回两个日期之间的天数(负数代表前一个参数代表的日期比较小) |
DATE_FORMAT |
DATE_FORMAT(NOW(),'%m-%d-%Y') |
08-16-2019 |
用给定的格式显示日期和时间 |
常见时间单位
| 时间单位 | 描述 |
|---|---|
MICROSECOND |
毫秒 |
SECOND |
秒 |
MINUTE |
分钟 |
HOUR |
小时 |
DAY |
天 |
WEEK |
星期 |
MONTH |
月 |
QUARTER |
季度 |
YEAR |
年 |
6.3 数值处理函数
| 名称 | 调用示例 | 示例结果 | 描述 |
|---|---|---|---|
ABS |
ABS(-1) |
1 |
取绝对值 |
Pi |
PI() |
3.141593 |
返回圆周率 |
COS |
COS(PI()) |
-1 |
返回一个角度的余弦 |
EXP |
EXP(1) |
2.718281828459045 |
返回e的指定次方 |
MOD |
MOD(5,2) |
1 |
返回除法的余数 |
RAND |
RAND() |
0.7537623539136372 |
返回一个随机数 |
SIN |
SIN(PI()/2) |
1 |
返回一个角度的正弦 |
SQRT |
SQRT(9) |
3 |
返回一个数的平方根 |
TAN |
TAN(0) |
0 |
返回一个角度的正切 |
7 COUNT 函数
COUNT函数使用来统计行数的,有下边两种使用方式:
COUNT(*):对表中行的数目进行计数,不管列的值是不是NULL。COUNT(列名):对特定的列进行计数,会忽略掉该列为NULL的行。
两者的区别是会不会忽略统计列的值为NULL的行。
8 查询
where 竟然可以这么写😇
select *
from edge
where (ip, mode) = ('192.168.50.101', 2);in 竟然可以这么写😂
select *
from edge
where (ip, mode) in (select '192.168.50.101', 2);9 判断语句
9.1 if then
IF 表达式 THEN
处理语句列表
[ELSEIF 表达式 THEN
处理语句列表]
... # 这里可以有多个ELSEIF语句
[ELSE
处理语句列表]
END IF;9.2 case when
CASE WHEN 表达式 THEN 处理语句
else 表达式 end
## 或者
CASE when 表达式 then 处理语句
when 表达式 then 处理语句
... 可以与多个 when 表达式 then 处理语句
END示例:
select *,
CASE WHEN name='大彬' THEN '角色1'
else '角色2' end as processed_name ,
case when status = 1 then '已处理'
when status = 0 then '未处理'
when status = 2 then '待处理' end as processed_status
from user;10 循环语句
10.1 WHILE
WHILE 表达式 DO
处理语句列表
END WHILE;10.2 REPEAT
REPEAT
处理语句列表
UNTIL 表达式 END REPEAT;10.3 LOOP
LOOP
处理语句列表
END LOOP;在使用 LOOP 时可以使用RETURN语句直接让函数结束就可以达到停止循环的效果,也可以使用LEAVE语句,不过使用LEAVE
时,需要先在LOOP语句前边放置一个所谓的标记。
CREATE FUNCTION sum_all(n INT UNSIGNED)
RETURNS INT
BEGIN
DECLARE result INT DEFAULT 0;
DECLARE i INT DEFAULT 1;
flag:LOOP
IF i > n THEN
LEAVE flag;
END IF;
SET result = result + i;
SET i = i + 1;
END LOOP flag;
RETURN result;
END☝️示例中,在LOOP语句前加了一个flag:,相当于为这个循环打了一个名叫flag的标记,然后在对应的END LOOP
语句后边也把这个标记名flag
给写上了。在存储函数的函数体中使用LEAVE flag语句来结束flag这个标记所代表的循环。
标记主要是为了可以跳到指定的语句中
11 DUPLICATE KEY UPDATE
对于主键或者有唯一性约束的列或列组合来说,新插入的记录如果和表中已存在的记录重复的话,我们可以选择的策略不仅仅是忽略(INSERT IGNORE)该条记录的插入,也可以选择更新这条重复的旧记录。
CREATE TABLE `t`
(
`idt` int(11) NOT NULL AUTO_INCREMENT,
`phone` char(11) DEFAULT NULL,
`name` varchar(45) DEFAULT NULL,
PRIMARY KEY (`idt`),
UNIQUE KEY `idt_UNIQUE` (`idt`),
UNIQUE KEY `phone_UNIQUE` (`phone`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8如上表,idt 是唯一主键,phone 是 UNIQUE 唯一约束。

表里有条记录 phone = 15212124125,name = '吴彦祖',现在再添加一条记录,phone 跟 name = '吴彦祖'
是一样的,但是 name='宋江'
INSERT INTO t (phone, name)
VALUES ('15212124125', '宋江') ON DUPLICATE KEY
UPDATE name = '宋江';
-- 对于批量插入可以这么写,`VALUES(列名)`的形式来引用待插入记录中对应列的值
INSERT INTO t (phone, name)
VALUES ('15212124125', '宋江'),
('15212124126', '李逵') ON DUPLICATE KEY
UPDATE name =
VALUES (`name`);结果:
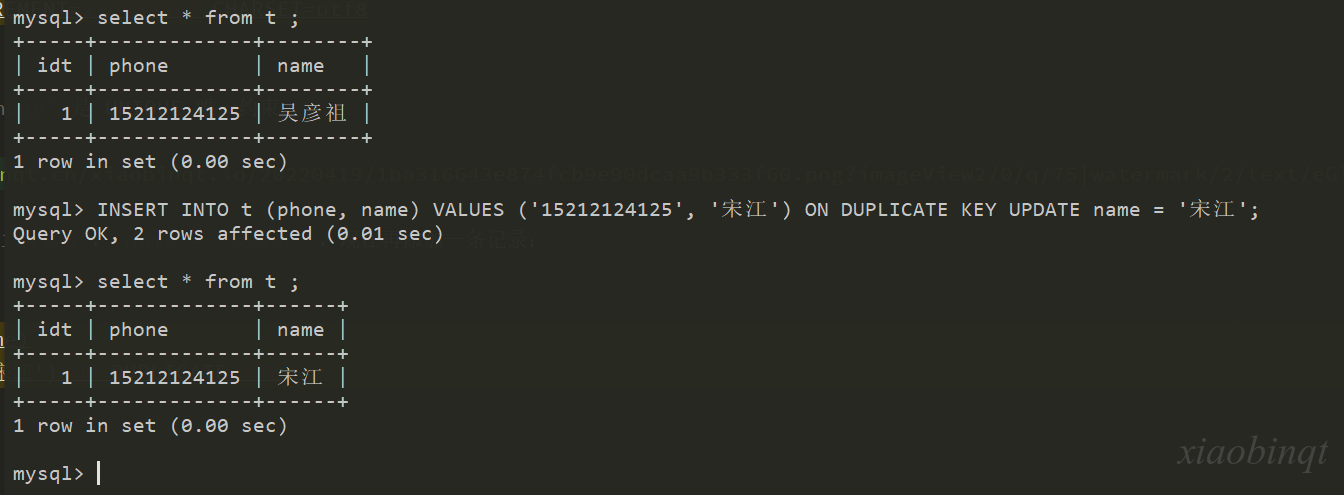
由结果可知,phone 电话的值没有改变,但是 name 被修改成了宋江。
也就是说,如果 t 表中已经存在 phone 的列值为 15212124125 的记录(因为 phone列具有UNIQUE
约束),那么就把该记录的 name列更新为'宋江'。
对于那些是主键或者具有UNIQUE约束的列或者列组合来说,如果表中已存在的记录中有与待插入记录在这些列或者列组合上重复的值,我们可以使用VALUES(列名)的形式来引用待插入记录中对应列的值
12 自定义变量
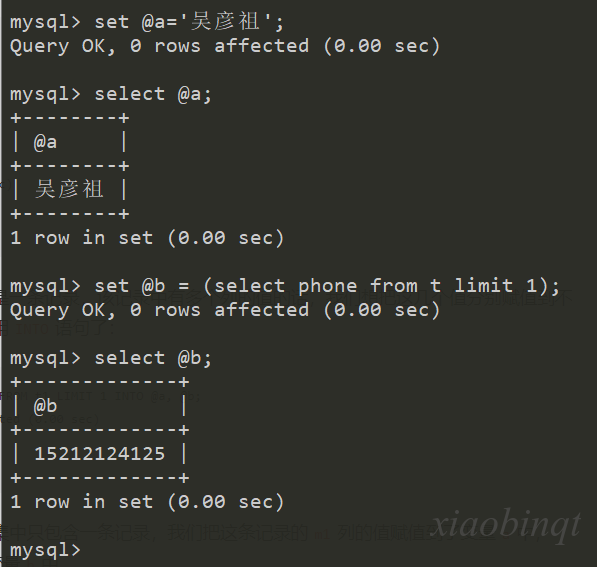
12.1 单个变量
设置单个变量可以使用 SET 关键字。
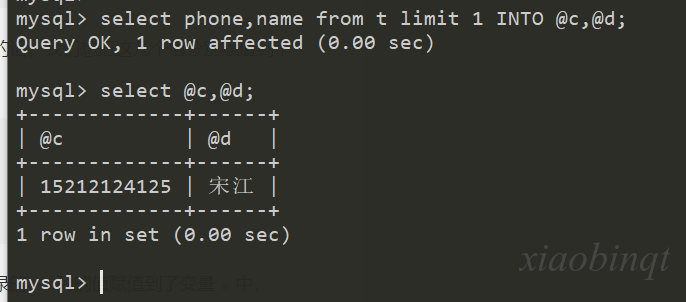
12.2 多个变量
设置多个变量可以使用 INTO 关键字。
13 索引建立原则
- 频繁用作查询条件的字段应酌情考虑为其创建索引。
- 表的主外键或连表字段,必须建立索引,因为能很大程度提升连表查询的性能。
- 建立索引的字段,一般值的区分性要足够高,这样才能提高索引的检索效率。
- 建立索引的字段,值不应该过长,如果较长的字段要建立索引,可以选择前缀索引。
- 建立联合索引,应当遵循最左前缀原则,将多个字段之间按优先级顺序组合。
- 经常根据范围取值、排序、分组的字段应建立索引,因为索引有序,能加快排序时间。
- 对于唯一索引,如果确认不会利用该字段排序,那可以将结构改为
Hash结构。 - 尽量使用联合索引代替单值索引,联合索引比多个单值索引查询效率要高。
14 新建索引需要注意哪些
- 值经常会增删改的字段,不合适建立索引,因为每次改变后需维护索引结构。
- 一个字段存在大量的重复值时,不适合建立索引,比如性别字段。
- 索引不能参与计算,因此经常带函数查询的字段,并不适合建立索引。
- 一张表中的索引数量并不是越多越好,一般控制在3个,最多不能超过5个。
- 建立联合索引时,一定要考虑优先级,查询频率最高的字段应当放首位。
- 当表的数据较少,不应当建立索引,因为数据量不大时,维护索引反而开销更大。
- 索引的字段值无序时,不推荐建立索引,因为会造成页分裂,尤其是主键索引。
15 如何正确使用索引,哪些情况会导致索引失效
- 查询 SQL 中尽量不要使用
OR关键字,可以使用子查询代替。 - 模糊查询尽量不要以
%开头,如果实在要实现这个功能可以建立全文索引。 - ⚠️编写 SQL 时一定要注意字段的数据类型,否则 MySQL 的隐式转换会导致索引失效。
- 一定不要在编写 SQL 时让索引字段执行计算工作,尽量将计算工作放在客户端中完成。
- 对于索引字段尽量不要使用计算类函数,一定要使用时请记得将函数计算放在
=后面。 - 多条件的查询 SQL 一定要使用联合索引中的第一个字段,否则会打破最左匹配原则。
- 对于需要对比多个字段的查询业务时,可以拆分为连表查询,使用临时表代替。
- 在 SQL 中不要使用反范围性的查询条件,大部分反范围性、不等性查询都会让索引失效。