Go Slice 实现原理
1 什么是 slice
切片是基于数组实现的,它的底层是数组,可以理解为对底层数组的抽象。
源码包中 src/runtime/slice.go 定义了 slice 的数据结构:
type slice struct {
array unsafe.Pointer // ArbitraryType int
len int
cap int
}array 是指向底层数组的指针,占用 8 个字节。len 是切片的长度,占用 8 个字节。cap 是切片的容量,cap 总是大于等于 len 的,占用 8 个字节。所以 slice 占用 24 个字节。
slice 有 4 种初始化方式
// 初始化方式1:直接声明
var slice1 []int
// 初始化方式2:使用字面量
slice2 := []int{1, 2, 3, 4}
// 初始化方式3:使用 make 创建slice
slice3 := make([]int, 3, 5)
// 初始化方式4: 从切片或数组截取
slcie4 := arr[1:3]可以通过下面的代码,看下 slice 初始化调用的底层函数:
package main
import "fmt"
func main() {
slice := make([]int, 0)
slice = append(slice, 1)
fmt.Println(slice, len(slice), cap(slice))
}通过 go tool compile -S main.go | grep CALL 得到汇编代码
0x0032 00050 (main.go:6) CALL runtime.makeslice(SB)
0x004b 00075 (main.go:7) CALL runtime.growslice(SB)
0x0076 00118 (main.go:8) CALL runtime.convTslice(SB)
0x0091 00145 (main.go:8) CALL runtime.convT64(SB)
0x00ac 00172 (main.go:8) CALL runtime.convT64(SB)
0x00e0 00224 ($GOROOT/src/fmt/print.go:274) CALL fmt.Fprintln(SB)
0x00f5 00245 (main.go:5) CALL runtime.morestack_noctxt(SB)初始化 slice 调用的是 runtime.makeslice,makeslice 函数的工作主要就是计算 slice 所需内存大小,然后调用 mallocgc 进行内存的分配。
所需内存大小 = 切片中元素大小 * 切片的容量。
package runtime
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// NOTE: Produce a 'len out of range' error instead of a
// 'cap out of range' error when someone does make([]T, bignumber).
// 'cap out of range' is true too, but since the cap is only being
// supplied implicitly, saying len is clearer.
// See golang.org/issue/4085.
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}2 array 和 slice 区别
-
数组初始化必须指定长度,并且长度就是固定的 切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
-
数组是值类型,将一个数组赋值给另一个数组时,传递的是一份深拷贝,函数传参操作都会复制整个数组数据,会占用额外的内存,函数内对数组元素值的修改,不会修改原数组内容。切片是引用类型,将一个切片赋值给另一个切片时,传递的是一份浅拷贝,函数传参操作不会拷贝整个切片,只会复制 len 和 cap,底层共用同一个数组,不会占用额外的内存,函数内对数组元素值的修改,会修改原数组内容。
-
数组需要遍历计算数组长度,时间复杂度为 O(n) 切片底层包含 len 字段,可以通过 len() 计算切片长度,时间复杂度为 O(1)
3 slice 扩容机制
3.1 旧规则存在的问题
在 1.17 及之前的版本中,扩容机制是这样的👇:
-
当新切片需要的容量 cap 大于两倍扩容的容量,则直接按照新切片需要的容量扩容;
-
当原 slice 容量 < 1024 的时候,新 slice 容量变成原来的 2 倍;
-
当原 slice 容量 > 1024,进入一个循环,每次容量变成原来的1.25倍,直到大于期望容量。
slice 扩容时会调用 runtime.growslice。这里只关注该函数 slice 计算容量部分的逻辑,计算方法如下:
// 1.17及以前的版本中
// old指切片的旧容量, cap指期望的新容量
func growslice(old, cap int) int {
newcap := old
doublecap := newcap + newcap
// 如果期望容量大于旧容量的2倍,则直接使用期望容量作为最终容量
if cap > doublecap {
newcap = cap
} else {
// 如果旧容量小于1024,则直接翻倍
if old < 1024 {
newcap = doublecap
} else {
// 每次增长大约1.25倍
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
// 这里忽略了对齐操作
return newcap
}这个扩容机制令一些人产生了一些困惑,因为它会产生一些 “看起来不那么自然的行为”。比如它计算出来的新容量不是单调递增的,下面的程序会将不同容量 slice 的扩容结果打印出来:
package main
import (
"fmt"
)
func main() {
for i := 0; i < 2000; i += 100 {
fmt.Println(i, cap(append(make([]bool, i), true)))
}
}该程序的输出如下(旧版本的扩容规则):
// 第一列是切片的旧容量
// 第二列是扩容后的容量
0 8
100 208
200 416
300 640
400 896
500 1024
600 1280
700 1408
800 1792
900 2048
1000 2048
1100 1408 <-- 在这个点,扩容后的新容量比上面的容量要小
1200 1536
1300 1792
1400 1792
1500 2048
1600 2048
1700 2304
1800 2304
1900 2688可以看到,在 slice 的容量刚刚触发大于 1024 增长 1.25 倍这个条件的时候,计算出来的新容量要小于之前计算出的容量,这里绘制了一张图表,可以感受一下:
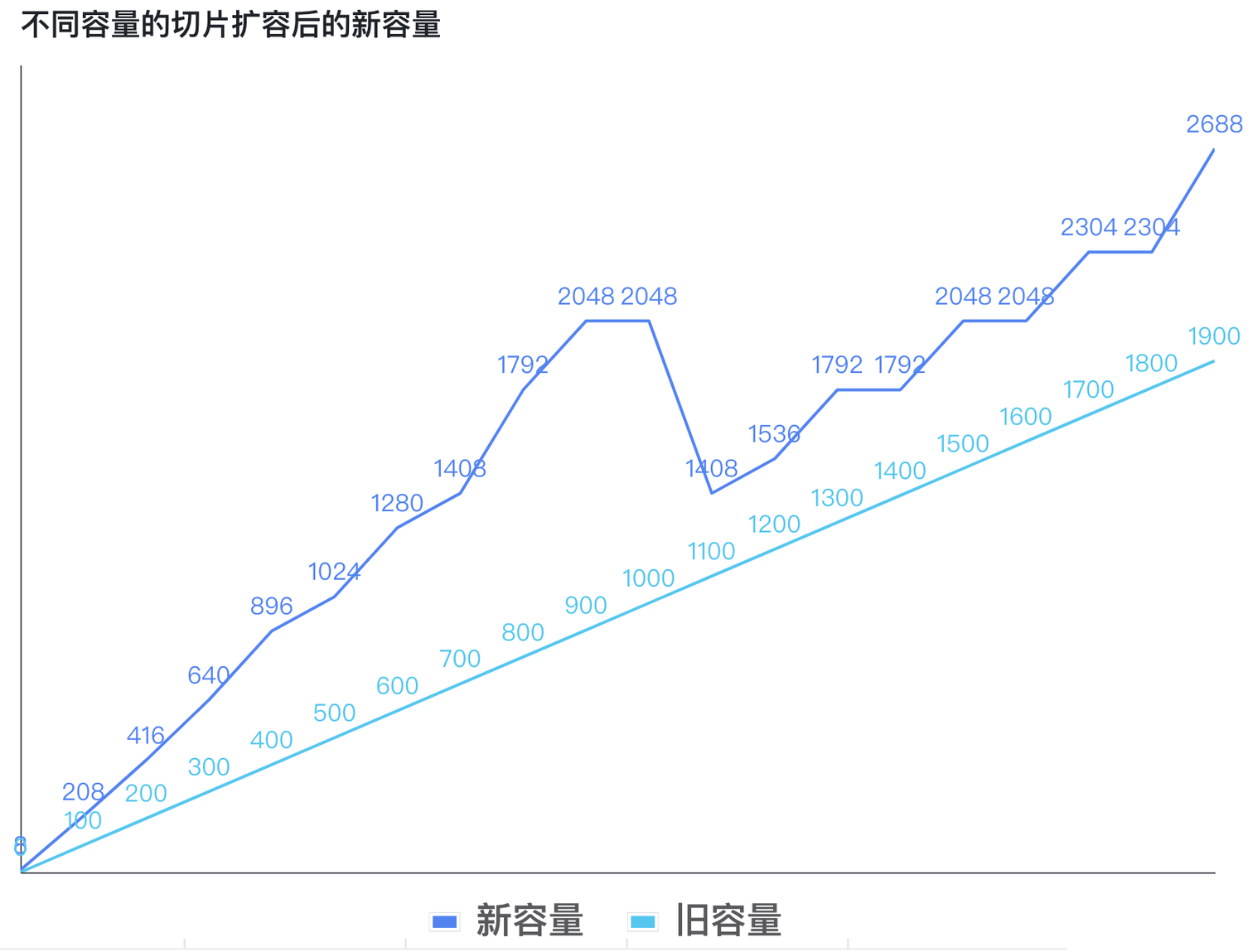
3.2 更加平滑的扩容算法
从 go1.18 开始,slice 容量的计算方法被改为了这样:
// 只关心扩容规则的简化版growslice
func growslice(old, cap int) int {
newcap := old
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256 // 不同点1
if old < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += (newcap + 3*threshold) / 4 // 不同点2
}
if newcap <= 0 {
newcap = cap
}
}
}
return newcap
}新版的扩容算法相较于旧的有两处不同,首先是双倍容量扩容的最大阈值从 1024 降为了 256,只要超过了 256,就开始进行缓慢的增长。其次是增长比例的调整,之前超过了阈值之后,基本为恒定的 1.25 倍增长,而现在超过了阈值之后,增长比例是会动态调整的:
-
当新切片需要的容量 cap 大于两倍扩容的容量,则直接按照新切片需要的容量扩容;
-
当原 slice 容量 < threshold(256) 的时候,新 slice 容量变成原来的 2 倍;
-
当原 slice 容量 > threshold(256),进入一个循环,每次容量增加
(旧容量+3*threshold)/4。
初始长度 增长比例
256 2.0
512 1.63
1024 1.44
2048 1.35
4096 1.30可以看到,随着切片容量的变大,增长比例逐渐向着 1.25 进行靠拢。
这次更改之后,slice 扩容整体的增长曲线变得更加平滑:

关于更多信息,可以查看#2dda92ff6f9f07eeb110ecbf0fc2d7a0ddd27f9d
4 slice 是否是线程安全的
线程安全的定义是:
多个线程访问(读)同一个对象时,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。
若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
Go 语言实现线程安全常用的方式有:
- 互斥锁
- 读写锁
- 原子操作
- sync.once
- sync.atomic
- channel
slice 底层结构并没有使用加锁等方式,不支持并发读写,所以 slice 并不是线程安全的,使用多个 goroutine 对类型为 slice 的变量进行操作,每次输出的值大概率都不会一样,与预期值不一致,slice 在并发执行中不会报错,但是数据可能会丢失。
package main
import (
"log"
"sync"
)
// 切片非并发安全* 多次执行,每次得到的结果都不一样* 可以考虑使用 channel 本身的特性 (阻塞) 来实现安全的并发读写
func main() {
TestSliceConcurrencySafe()
}
func TestSliceConcurrencySafe() {
a := make([]int, 0)
var wg sync.WaitGroup
for i := 0; i < 10000; i++ {
wg.Add(1)
go func(i int) {
a = append(a, i)
wg.Done()
}(i)
}
wg.Wait()
log.Fatalln(len(a)) // 这里的值不是 10000
}