Go GMP 调度模型

1 进程、线程、协程的区别
进程:进程是操作系统为应用程序分配资源的最小单元。每个进程有独立的内存空间和状态。
线程:线程是进程中的一个独立执行单元。在 Go 中,一个进程可以启动多个线程,以并行执行任务。
协程:协程是 Go 语言中的一种轻量级的并发技术。它是用户态的,不需要操作系统的支持,可以在单个线程中启动多个协程,并行执行任务。协程共享同一个线程的资源,但拥有自己的栈和寄存器。
总的来说,进程和线程是操作系统级别的并发技术,用于在多核处理器上利用资源;而协程是 Go 语言提供的一种高效、轻量级的并发技术,用于实现程序内部的并发任务。
1.1 进程
进程是操作系统对一个正在运行的程序的一种抽象,进程是资源分配的最小单位,每一个进程都有一个自己的地址空间。
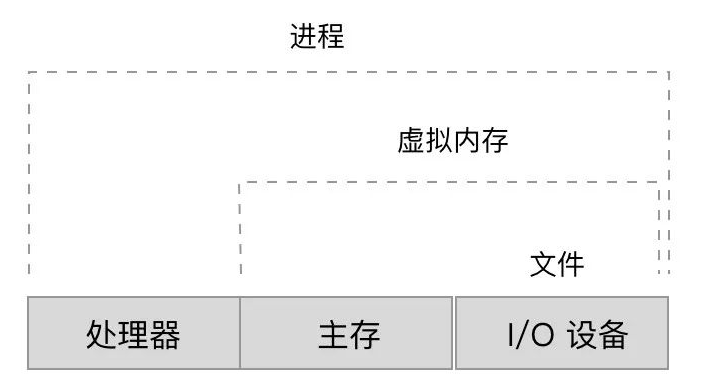
通俗的说,进程就是一个正在执行的程序。
进程存在的意义是为了合理压榨 CPU 的性能和分配运行的时间片,让 CPU 不能 “闲着“。
在计算机中,其计算核心是 CPU,负责所有计算相关的工作和资源。单个 CPU 一次只能运行一个任务。如果一个进程跑着,就把唯一一个 CPU 给完全占住,那是非常不合理的。
如果总是在运行一个进程上的任务,就会出现一个现象,就是任务不一定总是在执行 “计算型” 的任务,会有很大可能是在执行网络调用阻塞了,那么 CPU 岂不就浪费了?
所以出现了多进程,多个 CPU,多个进程。多进程就是指计算机系统可以同时执行多个进程,从一个进程到另外一个进程的转换是由操作系统内核管理的,一般是同时运行多个软件。
1.2 线程
有了多进程,在操作系统上可以同时运行多个进程。那么为什么有了进程,还要线程呢?这是因为:
- 进程间的信息难以共享数据,父子进程并未共享内存,需要通过进程间通信(IPC),在进程间进行信息交换,性能开销较大。
- 创建进程(一般是调用
fork方法)的性能开销较大。
所以大家又把目光转向了进程内,能不能在进程里做点什么呢?

一个进程可以由多个称为线程的执行单元组成。每个线程都运行在进程的上下文中,共享着同样的代码和全局数据。
多个进程,就可以有更多的线程。多线程比多进程之间更容易共享数据,在上下文切换中线程一般比进程更高效。这是因为,
- 线程之间能够非常方便、快速地共享数据。 只需将数据复制到进程中的共享区域就可以了,但需要注意避免多个线程修改同一份内存。
- 创建线程比创建进程要快 10 倍甚至更多。 线程都是同一个进程下自家的孩子,像是内存页、页表等就不需要了。
1.3 协程
协程(Co-routine)是用户态的线程。通常创建协程时,会从进程的堆中分配一段内存作为协程的栈。
线程的栈有 8MB,而协程栈的大小通常只有 KB 级别,而 Go 语言的协程更夸张,只有 2-4KB,非常的轻巧。
协程有以下优势👋:
-
👉节省 CPU:避免系统内核级的线程频繁切换,造成的 CPU 资源浪费。而协程是用户态的线程,用户可以自行控制协程的创建于销毁,极大程度避免了系统级线程上下文切换造成的资源浪费。
-
👉节约内存:在 64 位的 Linux 中,一个线程需要分配 8MB 栈内存和 64MB 堆内存,系统内存的制约导致我们无法开启更多线程实现高并发。而在协程编程模式下,可以轻松有十几万协程,这是线程无法比拟的。
-
👉稳定性:线程之间通过内存来共享数据,这也导致了一个问题,任何一个线程出错时,进程中的所有线程都会跟着一起崩溃。
-
👉开发效率:使用协程在开发程序之中,可以很方便的将一些耗时的 IO 操作异步化,例如写文件、耗时 IO 请求等。
2 goroutine 是什么
Goroutine 是一个由 Go 运行时管理的轻量级线程,我们称为 “协程”。
go f(x, y, z)操作系统本身是无法明确感知到 Goroutine 的存在的,Goroutine 的操作和切换归属于 “用户态” 中。
Goroutine 由特定的调度模式来控制,以 “多路复用” 的形式运行在操作系统为 Go 程序分配的几个系统线程上。
同时创建 Goroutine 的开销很小,初始只需要 2-4k 的栈空间。Goroutine 本身会根据实际使用情况进行自伸缩,非常轻量。
Go 程序中没有语言级的关键字让你去创建一个内核线程,你只能创建 goroutine,内核线程只能由 runtime 根据实际情况去创建。
Go 运行时系统并没有内核调度器的中断能力,内核调度器会发起抢占式调度将长期运行的线程中断并让出 CPU 资源,让其他线程获得执行机会。
3 调度器的由来
在多进程/多线程的操作系统中,解决了早期的单进程操作系统进程阻塞的问题,因为一个进程阻塞 CPU 可以立刻切换到其他进程中去执行,而且调度 CPU 的算法可以保证在运行的进程都可以被分配到 CPU 的运行时间片,这样从宏观来看,似乎多个进程是在同时被运行。
但新的问题就出现了,进程拥有太多的资源,进程的创建、切换、销毁,都会占用很长的时间。CPU 虽然利用起来了,但如果进程过多,CPU 有很大的一部分都被用来进行进程调度。为了能提高 CPU 的利用率,这里就需要用到调度。
CPU 调度切换的是进程和线程,CPU 对进程和线程的态度是一样的,虽然线程看起来很好,但实际上多线程开发设计会变得很复杂,要考虑很多同步竞争的问题,比如锁、竞争冲突等。
一个线程其实分为 “内核态“ 线程和 “用户态” 线程。一个 “用户态线程” 必须要绑定一个 “内核态线程”,但是 CPU 并不知道有 “用户态线程” 的存在,CPU 只知道它运行的是一个 “内核态线程”。这里我们可以把内核线程依然叫线程,用户线程叫协程。既然一个协程可以绑定一个线程,那么能不能多个协程绑定在一个或者多个线程上呢!
4 协程和线程的映射
4.1 N:1 关系
N 个协程绑定 1 个线程。
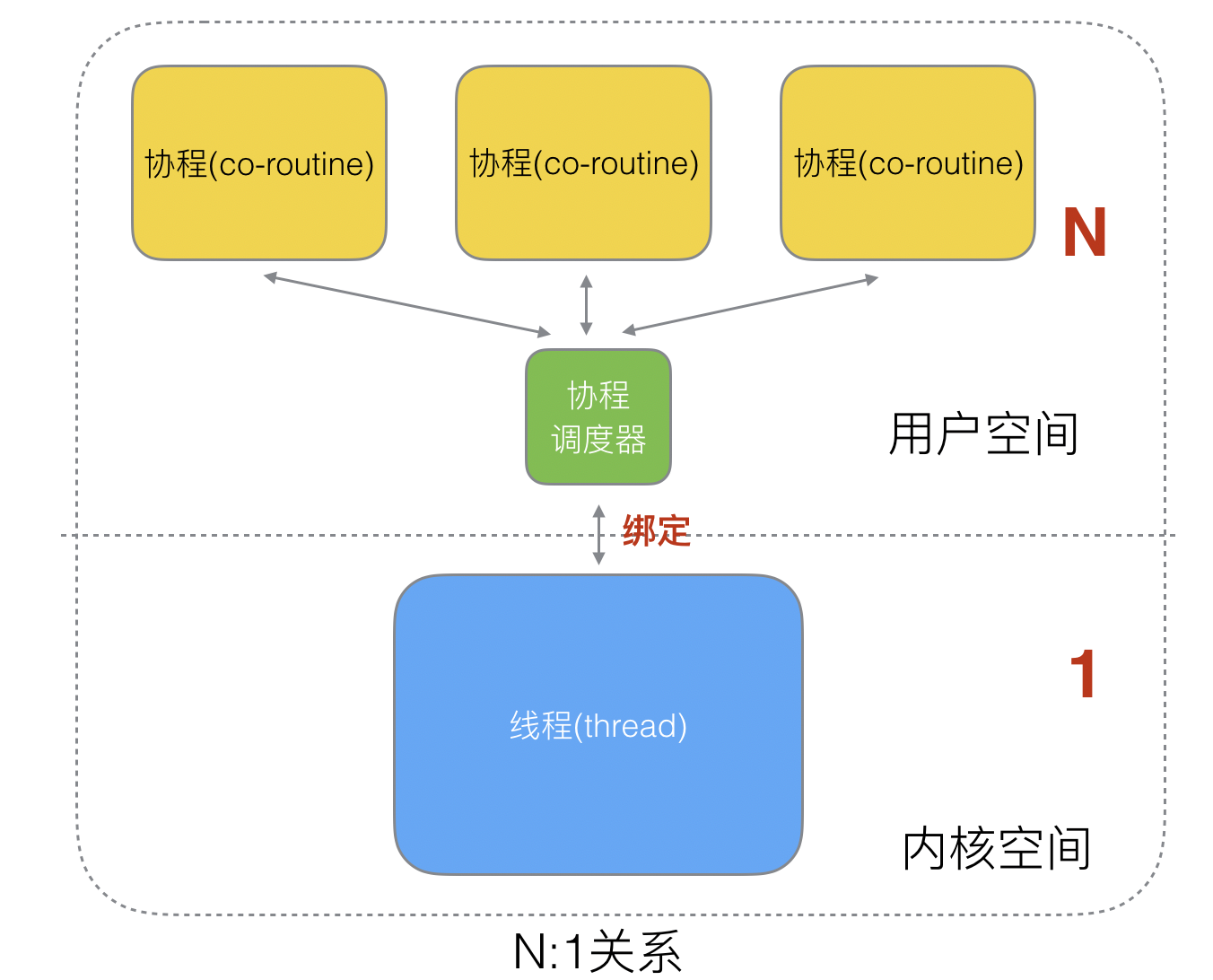
优点:
协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。但也有很大的缺点,1 个进程的所有协程都绑定在 1 个线程上。
缺点:
- 某个程序用不了硬件的多核加速能力
- 一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。
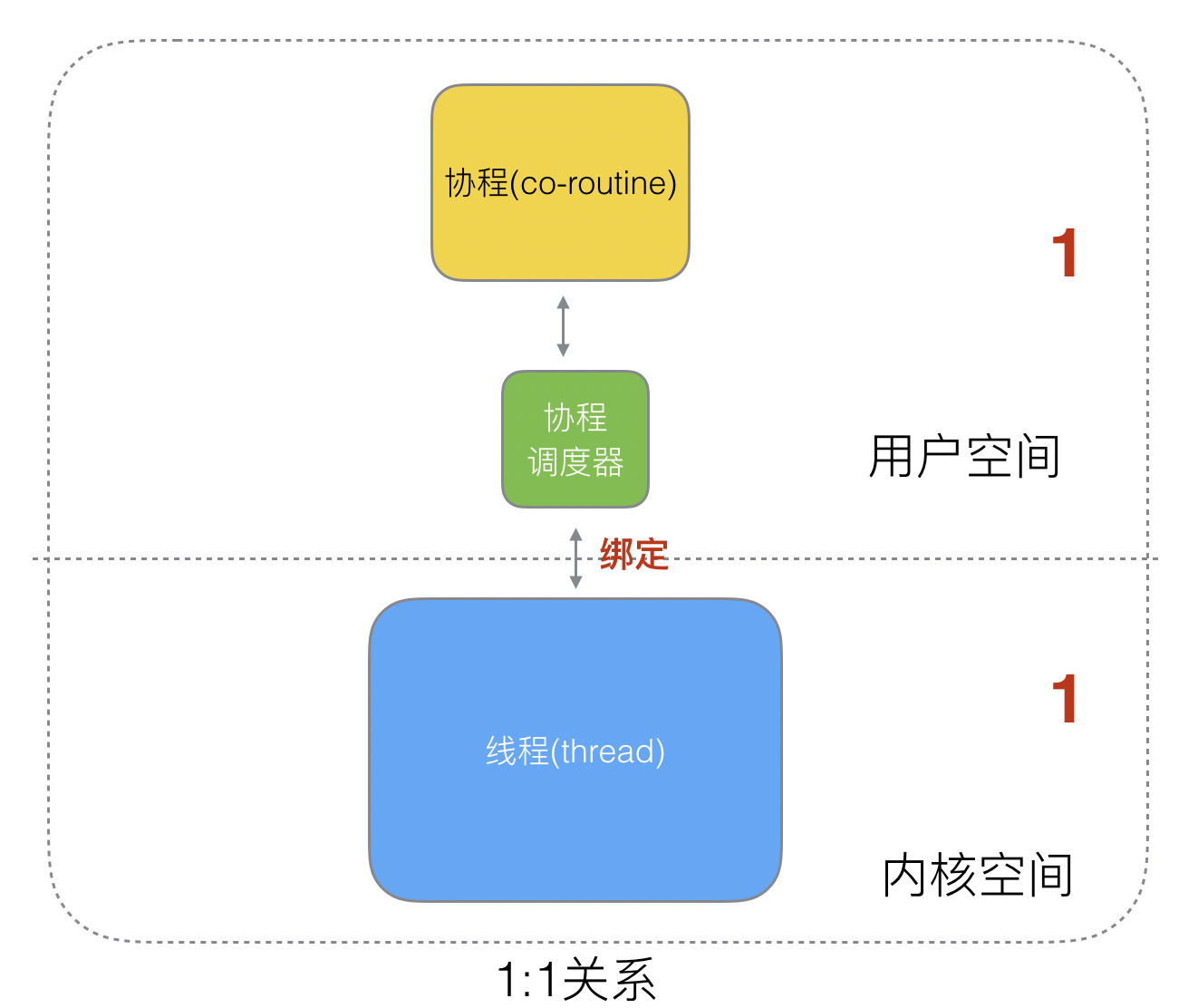
4.2 1:1 关系
1 个协程绑定 1 个线程,协程的调度都由 CPU 完成了,不存在N:1的缺点,但是协程的创建、删除和切换的代价都由 CPU 完成,略显昂贵。
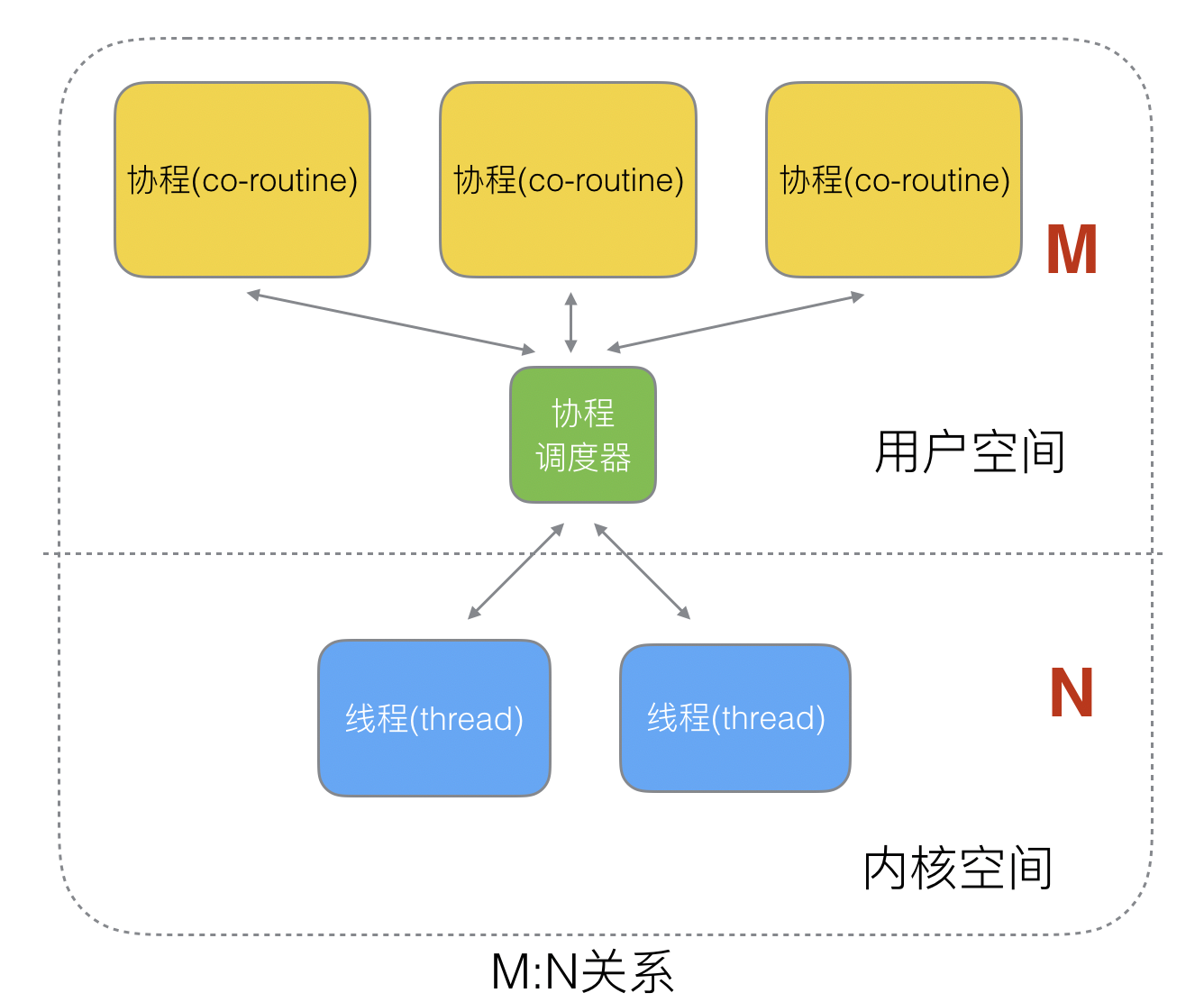
4.3 M:N 关系
M 个协程绑定 N 个线程,是N:1和1:1类型的结合,克服了以上 2 种模型的缺点,但实现复杂。
5 Go 的调度
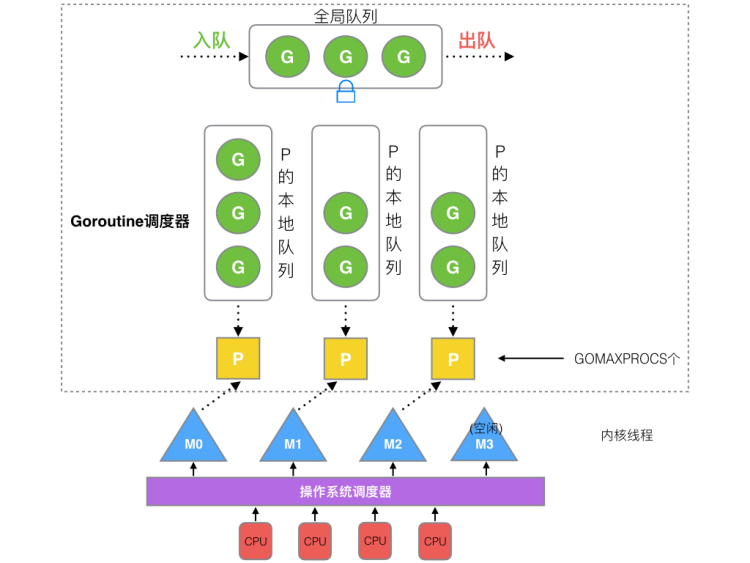
用户态的 Goroutine,操作系统看不到它 ,必然需要有某个东西去管理他,才能更好的运作起来。这就是 Go 语言中的调度,也就是 GMP 模型。
Go scheduler /ˈskedʒuːlər/ 的主要功能是针对在处理器上运行的 OS 线程分发可运行的 Goroutine,而我们一提到调度器,就离不开三个经常被提到的缩写,他们分别是:
-
G:Goroutine,实际上我们每次调用
go func就是生成了一个 G。 -
P:Processor,处理器,一般 P 的数量就是处理器的核数,可以通过
runtime.GOMAXPROCS(n)进行修改。P 包含了运行 goroutine 的资源,如果线程 M 想运行 goroutine,必须先获取 P ,一个 M 在与一个 P 关联之后形成了一个有效的 G 运行环境「内核线程 + 上下文环境」。P 中还包含了可运行的本地 G 队列,本地 G 队列不超过 256 个 G,优先会将新创建的 G 放到某个 P 的本地队列中,如果本地队列满了会放到全局队列中。 -
M:Machine,系统/内核线程,是运行 goroutine 的实体,每个 M 都代表了 1 个内核线程。M 可以运行 2 种代码,当 M 运行 go 代码一定需要一个P,当 M 运行原生代码, 例如阻塞的
syscall, 此时 M 不需要 P。
M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
这三者交互实际来源于 Go 的M:N调度模型,也就是 M 必须与 P 进行绑定,然后不断地在 M 上循环寻找可运行的 G 来执行相应的任务。
5.1 P和M何时被创建
P 何时创建:在确定了 P 的最大数量 n 后,运行时系统会根据这个数量创建 n 个 P。
M 何时创建 :没有足够的 M 来关联 P 并运行其中的可运行的 G。比如所有的 M 此时都阻塞住了,而 P 中还有很多就绪任务,就会去寻找空闲的 M,而没有空闲的,runtime 运行时就会去创建新的 M。当 M 有空闲就会被回收或是睡眠。
6 调度流程
-
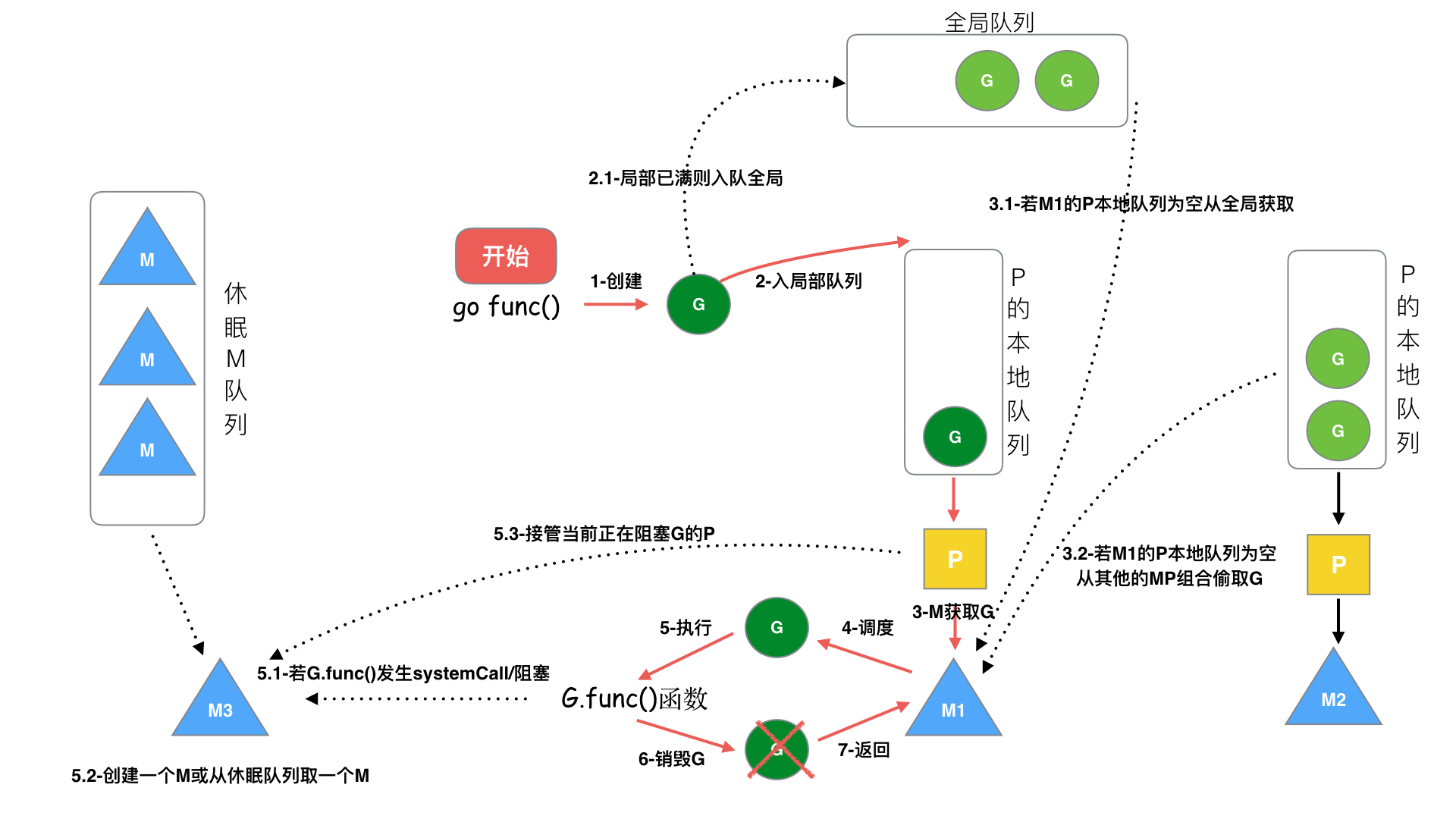
当我们执行
go func()时,实际上就是创建一个全新的 Goroutine,我们称它为 G。 -
新创建的 G 会被放入 P 的本地队列(Local Queue)或全局队列(Global Queue)中,准备下一步的动作。需要注意的一点,这里的 P 指的是创建 G 的 P,如果 P 的本地队列已经满了就会保存在全局的队列中。
-
唤醒或创建 M 以便执行 G。G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是
1:1的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会想其他的MP组合偷取一个可执行的 G 来执行。 -
一个 M 调度 G 执行的过程是一个循环机制。
-
当 M 执行某一个 G 的时候如果发生了
syscall或者其余的阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个 P。 -
当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态,加入到空闲线程中,然后这个 G 会被放入全局队列中。
在描述中有提到全局和本地这两类队列,其实在功能上来讲都是用于存放正在等待运行的 G,但是不同点在于,本地队列有数量限制,不允许超过 256 个。
并且在新建 G 时,会优先选择 P 的本地队列,如果本地队列满了,则将 P 的本地队列的一半的 G 移动到全局队列。 可以理解为调度资源的共享和再平衡。
7 M0和G0
M0是启动程序后编号为 0 的主线程,这个 M 对应的实例会在全局变量runtime.m0中,M0负责执行初始化操作和启动第一个 G, 在之后M0就和其他的 M 一样。
G0是每次启动一个 M 都会第一个创建的 gourtine,G0仅用于负责调度 G,G0不指向任何可执行的函数, 每个 M 都会有一个自己的G0。
package main
import "fmt"
func main() {
fmt.Println("Hello world")
}☝️上面代码会经历如下过程:
- runtime 创建最初的线程 m0 和 goroutine g0,并把 2 者关联。
- 调度器初始化:初始化 m0、栈、垃圾回收,以及创建和初始化由
GOMAXPROCS个 P 构成的 P 列表。 - 示例代码中的 main 函数是
main.main,runtime 中也有 1 个 main 函数runtime.main,代码经过编译后,runtime.main会调用main.main,程序启动时会为runtime.main创建 goroutine,可以称它为 main goroutine,然后把 main goroutine 加入到 P 的本地队列。 - 启动 m0,m0 已经绑定了 P,会从 P 的本地队列获取 G,获取到 main goroutine。
- M 根据 G 中的栈信息和调度信息设置运行环境,M 运行 G。
- G 退出,再次回到 M 获取可运行的 G,这样重复下去,直到
main.main退出,runtime.main执行 Defer 和 Panic 处理,或调用runtime.exit退出程序。
调度器的生命周期几乎占满了一个 Go 程序的一生,runtime.main的 goroutine 执行之前都是为调度器做准备工作,runtime.main的 goroutine 运行,才是调度器的真正开始,直到runtime.main结束而结束。
8 窃取行为
当创建新的 G 或者 G 变成可运行状态时,它会被推送加入到当前 P 的本地队列中。当 P 执行 G 完毕后,P 会将 G 从本地队列中弹出,同时会检查当前本地队列是否为空,如果为空不会立刻销毁线程,而是会随机的从其他 P 的本地队列中尝试 窃取一半可运行的 G 到自己的名下。
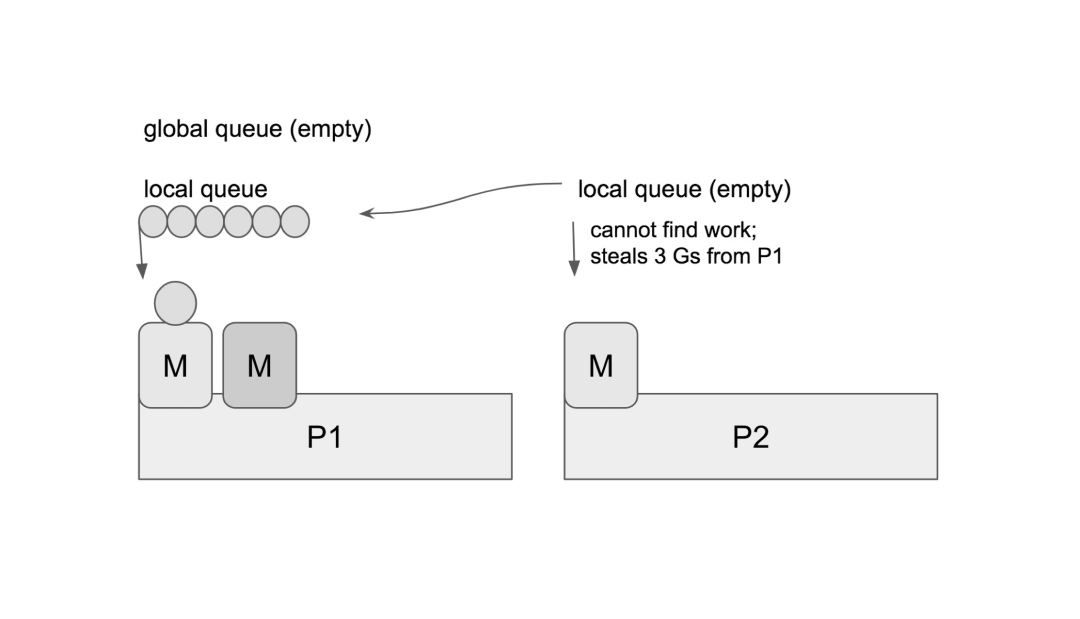
上图中👆,P2 在本地队列中找不到可以运行的 G,它会执行 work-stealing 调度算法,随机选择其它的处理器 P1,并从 P1 的本地队列中窃取了三个 G 到它自己的本地队列中去。至此,P1、P2 都拥有了可运行的 G,P1 多余的 G 也不会被浪费,调度资源将会更加平均的在多个处理器中流转。
9 限制条件
9.1 M 的限制
在协程的执行中,真正干活的是 GPM 中的 M(系统线程) ,因为 G 是用户态上的东西,最终执行都是得映射,对应到 M 这一个系统线程上去运行。
那么 M 有没有限制呢?
答案是:有的。在 Go 语言中,M 的默认数量限制是 10000,如果超出则会报错:
GO: runtime: program exceeds 10000-thread limit但是通常只有在 Goroutine 出现阻塞操作的情况下,才会遇到这种情况。这可能也预示着你的程序有问题。
若确切是需要那么多,还可以通过 debug.SetMaxThreads 方法进行设置。
9.2 G 的限制
Goroutine 的创建数量是否有限制?
答案是:没有。但理论上会受内存的影响,假设一个 Goroutine 创建需要 4k 的连续的内存块:
4k * 80,000 = 320,000k ≈ 0.3G内存
4k * 1,000,000 = 4,000,000k ≈ 4G内存
以此就可以相对计算出来一台单机在通俗情况下,所能够创建 Goroutine 的大概数量级别。
9.3 P 的限制
P 的数量是否有限制,受什么影响?
答案是:有限制。P 的数量受环境变量 GOMAXPROCS 的直接影响。
环境变量 GOMAXPROCS 又是什么?在 Go 语言中,通过设置 GOMAXPROCS,用户可以调整调度中 P(Processor)的数量。
另一个重点在于,与 P 相关联的的 M(系统线程),是需要绑定 P 才能进行具体的任务执行的,因此P 的多少会影响到 Go 程序的运行表现。
P 的数量基本是受本机的核数影响,没必要太过度纠结他。
那 P 的数量是否会影响 Goroutine 的数量创建呢?
答案是:不影响。且 Goroutine 多了少了,P 也该干嘛干嘛,不会带来灾难性问题。
9.4 小结
- M:有限制,默认数量限制是 10000,可调整。
- G:没限制,但受内存影响。
- P:受本机的核数影响,可大可小,不影响 G 的数量创建。
所以Goroutine 数量怎么预算,才叫合理?
在真实的应用场景中,如果你 Goroutine:
- 在频繁请求 HTTP,MySQL,打开文件等,那假设短时间内有几十万个协程在跑,那肯定就不大合理了(可能会导致 too many files open)。
- 常见的 Goroutine 泄露所导致的 CPU、Memory 上涨等,还是得看你的 Goroutine 里具体在跑什么东西。
跑的如果是 “资源怪兽”,只运行几个 Goroutine 都可以跑死。
10 为什么要有 P
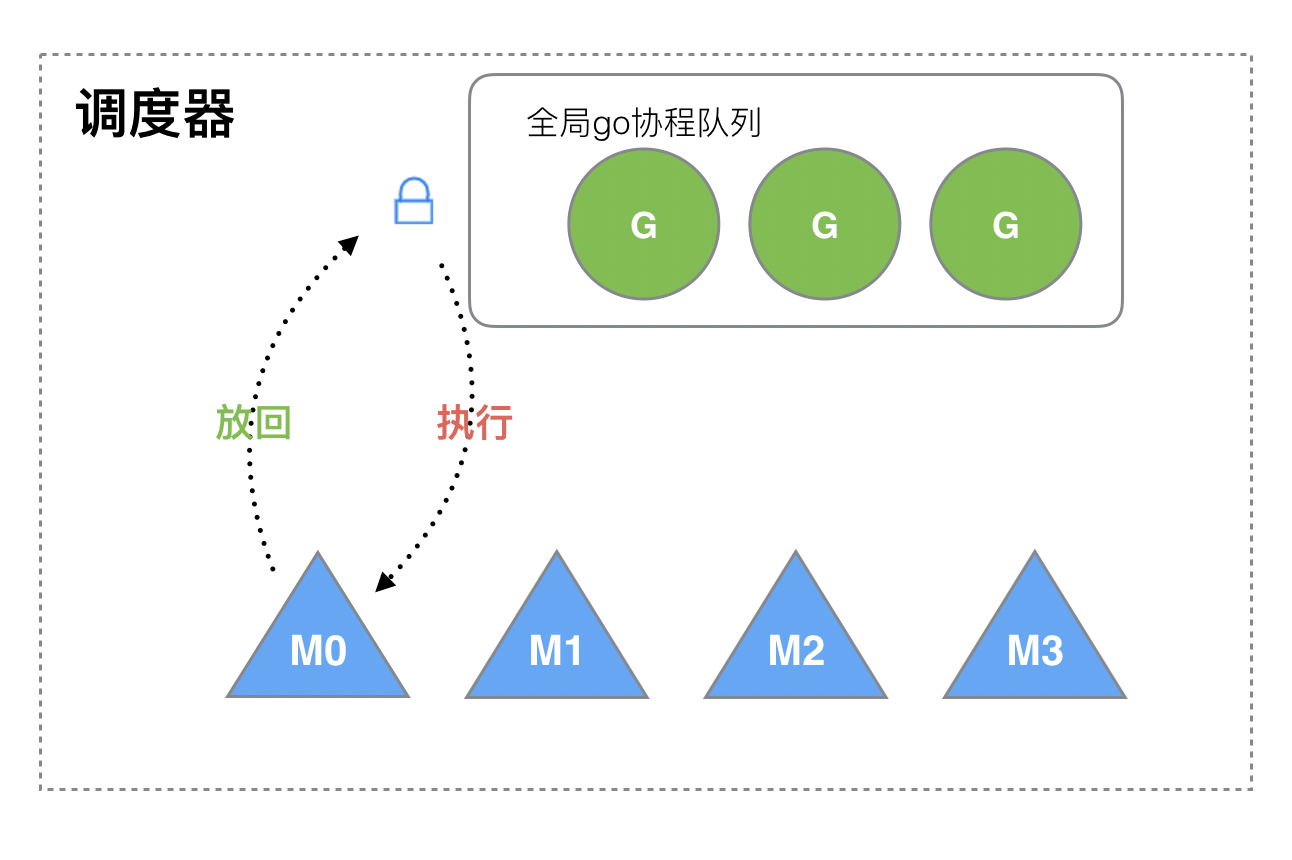
Go 早期的调度器是没有 P 的,只有 M 和 G。M 想要执行和放回 G 都必须访问全局 G 队列,并且 M 有多个,多线程访问同一资源需要加锁进行保证互斥/同步,所以全局 G 队列是有互斥锁进行保护的。
所以早期的调度器存在这样几个缺点:
- 创建、销毁、调度 G 都需要每个 M 获取锁,这就形成了激烈的锁竞争。
- M 转移 G 会造成延迟和额外的系统负载。比如当 G 中包含创建新协程的时候,M 创建了
G',为了继续执行 G,需要把G'交给M'执行,也造成了很差的局部性,因为G'和 G 是相关的,最好放在 M 上执行,而不是其他M'。 - 系统调用(CPU 在 M 之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
11 FAQ
- hand off 机制
当本线程上执行的 G 阻塞时,线程会释放绑定的 P,把 P 和 M 分离,把 P 转移给其他空闲的线程执行。
- 利用并行
可以通过GOMAXPROCS设置 P 的数量,最多有GOMAXPROCS个线程分布在多个 CPU 上同时运行,因为 P 是绑定在 M 上的,M 想要运行 G 必须先获取 P。GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
- 抢占
一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死。
- 自旋线程
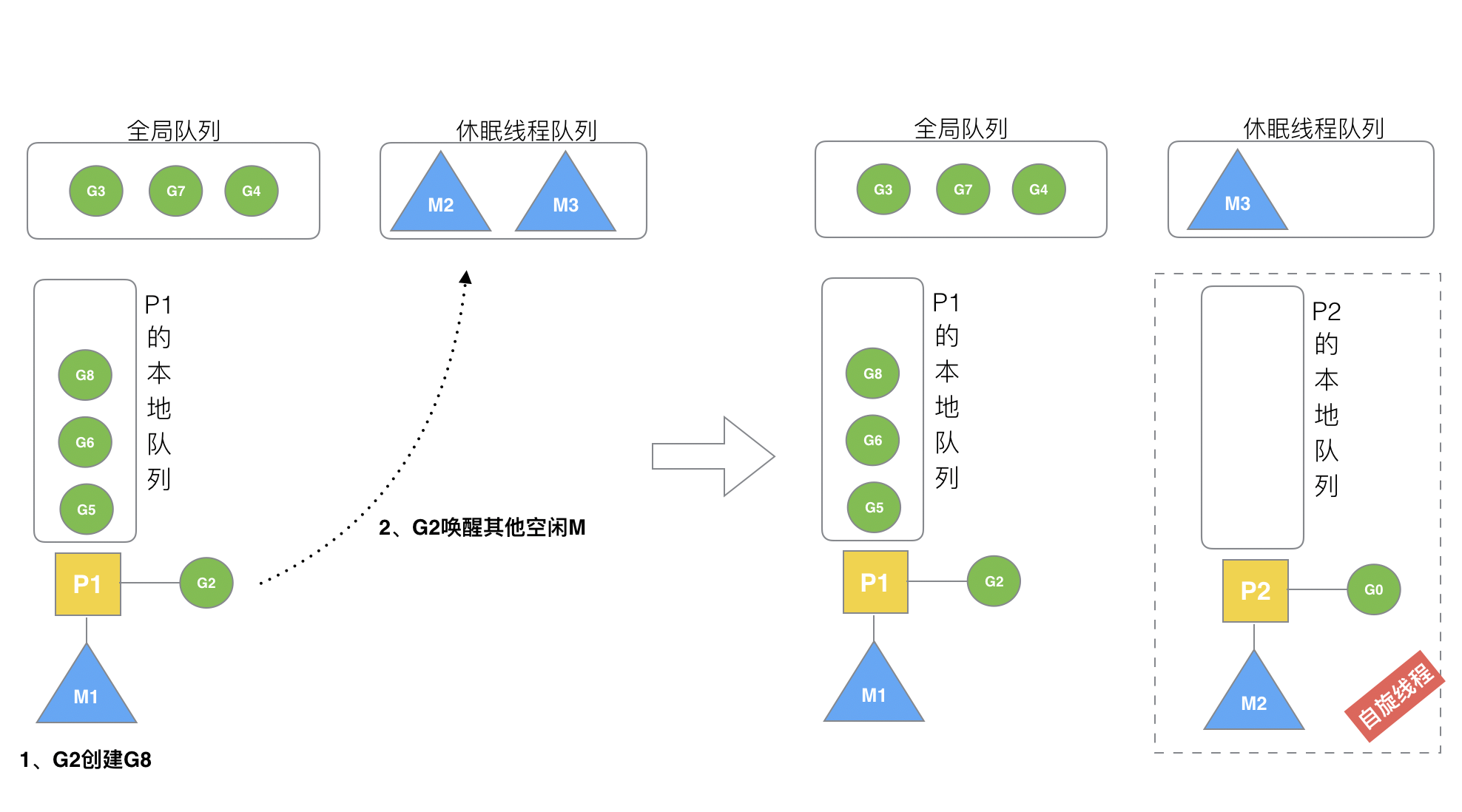
假定 G2 唤醒了 M2,M2 绑定了 P2,M2 调用并运行G0,但 P2 本地队列没有 G,M2 此时的状态称为自旋线程(没有 G 但为运行状态的线程,不断寻找 G)。自旋线程优先会从全局队列里获取 G,当全局队列里没有了时,会去其他的MP组合中偷取 G。
自旋线程的最大限制符合公式:自旋线程 + 执行线程 <= GOMAXPROCS
- 如何从全局队列取 G 的数量
某个 M 尝试从全局队列(简称 “GQ”)取一批 G 放到自己 P 的本地队列,从全局队列取的 G 数量符合下面的公式:
n = min(len(GQ) / GOMAXPROCS + 1, cap(LQ) / 2 )